
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Spring Boot가 해결하려고 했던 문제
- 스프링 제어역전
- 세션
- 스프링 에러
- 자바왕기초
- 자바
- 제이쿼리
- 오라클
- 오라클주별데이터
- 스프링
- 스프링 Ioc Container
- CSS
- jsp
- 스프링 Ioc
- 오라클통계
- 자바 기초
- 스프링과 스프링부트 차이점
- 스프링 구글차트로 기간별 현황 조회하기
- maven
- 스프링 구글차트
- 스프링 부트가 해결하려고 했던 문제
- 오라클클라우드에 젠킨스 설치하기
- HTML
- 자바 왕기초
- java
- 썸머노트
- 자바왕초보
- 오라클월별데이터
- 오라클일별데이터
- 자바기초
- Today
- Total
Just Do it
JPA(Java Persistence API)란 무엇인가 + 예제 실습 2 본문
출처: 코드로 배우는 스프링부트 웹 프로젝트. 구멍가게 코딩단, 남가람북스
2) 테스트 코드를 통한 CRUD 연습
- 작성한 MemoRepository를 이용해서 작성된 테이블에 SQL 없이 CRUD 작업을 테스트해 보자
- JpaRepository의 경우 다음과 같은 메서드를 활용한다.
* insert 작업: save(엔티티 객체)
* select 작업: findById(키 타입), getOne(키 타입)
* update 작업: save(엔티티 객체)
* delete 작업: deleteById(키 타입), delete(엔티티 객체)
- 특이하게 insert와 update 작업에 사용하는 메서드가 동일하게 save()를 이용하는데 이는 JPA의 구현체가 메모리상(Entity Manager라는 존재가 엔티티들을 관리하는 방식)에서 객체를 비교하고 없다면 insert, 존재한다면 update를 동작시키는 방식으로 동작하기 때문이다.
- 테스트 코드는 프로젝트 생성 시에 만들어진 test 폴더를 이용해서 'repository' 패키지를 작성하고 MemoRepositoryTests 클래스를 작성해서 진행한다.

- 본격적인 테스트에 앞서 실제로 MemoRepository가 정상적으로 스프링에서 처리되고, 의존성 주입에 문제가 없는지를 먼저 확인하는 것이 좋다.
- testClass() 메서드는 MemoRepository 인터페이스 타입의 실제 객체가 어떤 것인지 확인한다.
- 스프링이 내부적으로 해당 클래스를 자동으로 생성하는데(AOP 기능) 이때 클래스의 이름을 확인해보고자 한다.
- 테스트 코드는 'com.sun.proxy...'와 같이 작성한 적이 없는 클래스의 이름이 출력되는 것을 확인할 수 있다.
3) 등록 작업 테스트
등록 작업 테스트는 한 번에 여러 개의 엔티티 객체를 저장하도록 작성한다.

테스트의 최종결과는 DB를 조회해서 확인한다. (총 100개의 데이터가 들어감)

4) 조회 작업 테스트
- 조회 작업의 테스트는 findById()나 getOne()을 이용해서 엔티티 객체를 조회할 수 있다.
- findById()와 getOne()은 동작하는 방식이 조금 다른데, 데이터베이스를 먼저 이용하는지 나중에 필요한 순간까지 미루는 방식을 이용하는지에 대한 차이가 있다.

- findById()의 경우 java.util 패키지의 Optional 타입으로 반환되기 때문에 한번 더 결과가 존재하는지를 체크하는 형태로 작성하게 된다.
- 실행 시에는 아래와 같은 로그들이 기록되는 것을 볼 수 있다.

- 실행되는 결과를 보면 findById()를 실행한 순간에 이미 SQL은 처리가 되었고, '====' 부분은 SQL 처리 이후에 실행된 것을 볼 수 있다.
- getOne()의 경우는 조금 다른 방식으로 동작하는데 @Transactional 어노테이션이 추가로 필요하다.

- getOne()의 경우 리턴 값은 해당 객체이지만, 실제 객체가 필요한 순간까지 SQL을 실행하지는 않는다. 위의 코드를 실행하면 다음과 같은 결과를 볼 수 있다. 이전의 테스트 결과와 비교해보면 getOne()을 호출한 후에 '====' 부분이 먼저 실행되고 System.out.println()이 실행되면서 실제 객체를 사용하는 순간에 SQL이 동작하는 것을 확인할 수 있다.

5) 수정 작업 테스트
- 수정 작업은 등록 작업과 동일하게 save()를 이용해서 처리한다. 내부적으로 해당 엔티티의 @Id값이 일치하는지를 확인해서 insert 혹은 update 작업을 처리한다.

- testUpdate()를 보면 100번의 Memo 객체를 만들고, save()를 호출하고 있다. 흥미로운 점은 이 호출의 결과이다.

- 호출 결과를 보면 내부적으로 select 쿼리로 해당 번호의 Memo 객체를 확인하고, 이를 update 하는 것을 볼 수 있다.
- JPA는 엔티티 객체들을 메모리상에 보관하려고 하기 때문에 특정한 엔티티 객체가 존재하는지 확인하는 select가 먼저 실행되고 해당 @Id를 가진 엔티티 객체가 있다면 update, 그렇지 않다면 insert를 실행하게 된다.
6) 삭제 작업 테스트
- 삭제 작업도 위와 동일한 개념이 적용된다. 삭제하려는 번호(mno)의 엔티티 객체가 있는지 먼저 확인하고, 이를 삭제하려고 한다.

- deleteById()의 리턴 타입은 void이고 만일 해당 데이터가 존재하지 않으면 예외를 발생시킨다. 테스트 코드의 실행 결과는 select 이후에 delete 구문이 실행되는 방식으로 동작한다.

2.5 페이징/정렬 처리하기
- JPA는 내부적으로 페이징 처리를 'Dialect'라는 존재를 이용해서 처리한다.

- JPA가 이처럼 실제 데이터베이스에서 사용하는 SQL의 처리를 자동으로 하기 때문에 개발자들은 SQL이 아닌 API의 객체와 메서드를 사용하는 형태로 페이징 처리를 할 수 있다.
- Spring Data JPA에서 페이징 처리와 정렬은 특이하게도 findAll()이라는 메서드를 사용한다.
- findAll()은 JpaRepository 인터페이스의 상위인 PagingAndSortRepository의 메서드로 파라미터로 전달되는 Pageable이라는 타입의 객체에 의해서 실행되는 쿼리를 결정하게 된다.
- 단 한 가지 주의할 사항은 리턴 타입을 Page<T> 타입으로 지정하는 경우에는 반드시 파라미터를 Pageable 타입을 이용해야 한다는 점이다.
2.5.1 Pageable 인터페이스
- 페이지 처리를 위한 가장 중요한 존재는 org.springframework.data.domain.Pageable 인터페이스이다.
- Pageable 인터페이스는 페이지 처리에 필요한 정보를 전달하는 용도의 타입으로, 인터페이스이기 때문에 실제 객체를 생성할 때는 구현체인 org.springframework.data.domain.PageRequest라는 클래스를 사용한다.
- PageRequest클래스의 생성자는 특이하게도 protected로 선언되어 있어 new를 이용할 수 없다.
- 객체를 생성하기 위해서는 static한 of()를 이용해서 처리한다.
- PageRequest 생성자를 보면, page, size, Sort라는 정보를 이용해서 객체를 생성한다.

- static 메서드인 of()의 경우 몇 가지의 형태가 존재하는데 이는 페이지 처리에 필요한 정렬 조건을 같이 지정하기 위해서이다.
* of(int page, int size): 0부터 시작하는 페이지 번호와 개수(size), 정렬이 지정되지 않음
* of(int page, int size, Sort.Direction direction, String...props): 0부터 시작하는 페이지 번호와 개수, 정렬의 방향과 정렬 기준 필드들
* of(int page, int size, Sort sort): 페이지의 번호와 개수, 정렬 관련 정보
- 실제로 페이지 처리와 정렬을 어떻게 사용하는지 실습을 통해서 알아보자
2.5.2 페이징 처리
- Spring Data JPA를 이용할 때 페이지 처리는 반드시 '0'부터 시작한다는 점을 기억해야만 한다.
- 이점을 주의하고 아래와 같은 테스트 코드를 작성해 본다.

- import 시에 org.springframework.data 관련 클래스들을 사용하도록 주의해야 한다.
- 테스트 코드에서는 PageRequest.of()를 이용해서 1페이지의 데이터 10개를 가져오기 위해 파라미터로 '0,10'을 전달하고 있다.
- 주의 깊게 봐야하는 부분 중 하나는 리턴 타입이 org.springframework.data.domain.Page라는 점이다.
- Page 타입이 흥미로운 이유는 단순히 해당 목록만으로 가져오는데 그치지 않고, 실제 페이지 처리에 필요한 전체 데이터의 개수를 가져오는 쿼리 역시 같이 처리하기 때문이다. (만일 데이터가 충분하지 않다면 데이터의 개수를 가져오는 쿼리를 실행하지 않는다.)
- 확실히 알아보기 위해 테스트 코드를 실행해보면 다음과 같은 SQL이 실행된다.

- 테스트 결과를 보면 첫 번째 쿼리에서는 MySQL에서 페이징 처리를 사용하는 limit 구문이 사용되는 것을 볼 수 있고, 두 번째 쿼리에서는 count()를 이용해서 전체 개수를 처리하는 것을 볼 수 있다.
- 위와 같이 findAll()에 Pageable 타입의 파라미터를 전달하면 페이징 처리에 관련된 쿼리들을 실행하고, 이 결과들을 이용해서 리턴 타입으로 지정된 Page<엔티티 타입> 객체로 저장한다.
-Page<엔티티 타입> 은 쿼리 결과를 사용하기 위한 여러 메서드를 지원한다. 테스트 코드에 내용을 좀 더 추가해서 이를 알아보자.
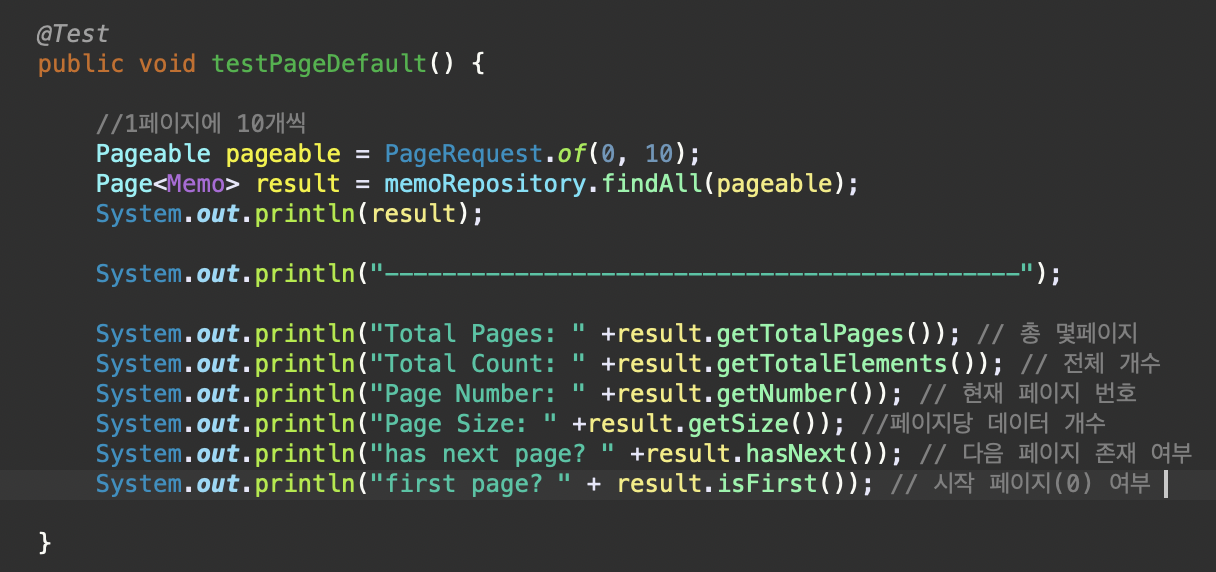
- 아래는 위의 테스트 코드의 결과이다.

- 10개씩 페이징 처리를 하기 때문에 전체 페이지 수는 10개이고, 199개의 데이터가 존재하는 등 필요한 정보를 가져오는 것을 볼 수 있다.
- 실제 페이지의 데이터를 처리하는 것은 getContent()를 이용해서 List<엔티티 타입>으로 처리하거나 Stream<엔티티 타입>을 반환하는 get()을 이용할 수 있다.

- 위 코드의 결과는 다음과 같이 출력된다. 출력된 결과의 정렬이 기본적으로 엔티티의 순차적인 순서임을 볼 수 있다.

2.5.3 정렬 조건 추가하기
- 페이징 처리를 담당하는 PageRequest에는 정렬과 관련된 org.springframework.data.domain.Sort 타입을 파라미터로 전달할 수 있다.
- Sort는 한 개 혹은 여러 개의 필드 값을 이용해서 순차적 정렬(asc)이나 역순으로 정렬(desc)을 지정할 수 있다.
- 간단한 테스트 코드를 통해 사용 방법을 확인하자

- 실행 결과 역시 mno의 역순으로 정렬되는 것을 확인할 수 있다.

- 정렬 조건은 Sort 객체의 and()를 이용해서 여러 개의 정렬 조건을 다르게 지정할 수 있다.
- 예를 들어 Memo 클래스의 memoText는 asc로 하고, mno는 desc로 지정하고 싶다면 다음과 같은 형태로 작성하게 된다.

- 위와 같은 코드의 경우 실행되는 쿼리에서는 다음과 같은 정렬 조건이 붙는 것을 볼 수 있다.

'신입 개발자가 되기 위해 공부했던 독학 자료들 > JPA' 카테고리의 다른 글
| JPA(Java Persistence API)란 무엇인가 + 예제 실습 1 (0) | 2022.04.05 |
|---|
