
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 스프링 구글차트
- 스프링 제어역전
- 자바 기초
- 오라클주별데이터
- jsp
- 자바기초
- Spring Boot가 해결하려고 했던 문제
- 오라클월별데이터
- 오라클통계
- 세션
- 자바왕기초
- CSS
- java
- 스프링 부트가 해결하려고 했던 문제
- 썸머노트
- 오라클
- 스프링 Ioc
- 자바왕초보
- 스프링 에러
- maven
- 오라클일별데이터
- 스프링과 스프링부트 차이점
- 제이쿼리
- HTML
- 자바 왕기초
- 스프링 Ioc Container
- 스프링 구글차트로 기간별 현황 조회하기
- 스프링
- 자바
- 오라클클라우드에 젠킨스 설치하기
- Today
- Total
Just Do it
CH 7 . 다중행 함수와 데이터 그룹화 본문
*출처: <비전공자도 기초부터 확실하게! 오라클로 배우는 데이터베이스 입문>, 이지훈, 이지스퍼블리싱
CH 7. 다중행 함수와 데이터 그룹화
- 다중행 함수: 여러 행을 바탕으로 하나의 결과 값을 도출내기 위해 사용하는 함수.
- 다중행 함수를 사용한 SELECT절에서는 기본적으로 여러 행이 결과로 나올 수 있는 열(함수 : 연산자가 사용된 데이터도 포함)을 함께 사용할 수 없다. 즉 다음과 같은 SELECT문은 실행되지 못하고 오류가 발생한다.

7-1. 하나의 열에 출력 결과를 담는 다중행 함수
1) 합계를 구하는 SUM 함수
-- 기본 형식
SUM([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[합계를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
-- 분석하는 용도 (OVER절 추가)
SUM([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[합계를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법을 지정)(선택)
1-1) SUM 함수와 DISTINCT, ALL 함께 사용하기
SELECT SUM(DISTINCT SAL), -- 중복 데이터 제외하고 계산
SUM(ALL SAL),
SUM(SAL)
FROM EMP;
- SUM 함수에 DISTINCT를 지정하면 같은 결과 값을 가진 데이터는 합계에서 한 번만 사용된다. 즉 중복 데이터는 제외하고 계산한다.
- 하지만 일반적으로 합계를 구할 때 같은 값을 제외하는 경우는 그리 많지 않으므로 보통은 SUM처럼 간단한 형식을 주로 사용한다.
2) 데이터 개수를 구해 주는 COUNT 함수
-- 기본 형식
COUNT([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[개수를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
-- 분석하는 용도 (OVER절 추가)
COUNT([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[개수를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법을 지정)(선택)- COUNT 함수에 *을 사용하면 SELECT문의 결과 값으로 나온 행 데이터의 개수를 반환해준다.
예) EMP 테이블의 총 행의 개수는 14개이다.

- 결과 값의 개수를 구하는 COUNT 함수는 언뜻 별 의미가 없어 보일 수도 있지만 WHERE절의 조건식을 함께 사용하면 유용하게 써먹을 수 있다. 예를 들어 30번 부서에서 근무하는 직원 수를 알고 싶다면 아래와 같이 SELECT 문을 작성할 수 있다.

- 이렇게 특정 조건을 만족하는 데이터를 COUNT 함수와 함께 사용한 결과 값은 다양한 분야에서 사용할 수 있다. 예를 들어 특정 웹 커뮤니티에서 특정 회원이 작성한 총 글 수, 댓글 수, 글에서 받은 찬성 수, 반대 수 등을 잘 조합하여 회원 등급이나 레벨 등을 관리할 수 있다. 또는 웹 쇼핑몰에서 어떤 상품이 많이 구매되었는지 화면의 어느 위치에 있는 항목이 자주 선택되었는지 등을 분석할 때도 활용할 수 있다.
- COUNT 함수는 NULL이 데이터로 포함되어 있을 경우, NULL 데이터는 반환 개수에서 제외한다.
3) 최댓값과 최솟값을 구하는 MAX, MIN 함수
-- 기본 형식
MAX ([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[최댓값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
-- 분석하는 용도 (OVER절 추가)
MAX([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[최댓값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법을 지정)(선택)-- 기본 형식
MIN ([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[최솟값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
-- 분석하는 용도 (OVER절 추가)
MIN([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[최솟값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법을 지정)(선택)- MAX, MIN 함수 역시 앞에서 다룬 SUM, COUNT 함수와 마찬가지로 DISTINCT나 ALL을 지정할 수 있지만, 최댓값과 최솟값은 데이터 중복 제거와 무관하게 같은 결과 값을 반환하기 때문에 실제로는 지정하지 않는다.


- 오라클 데이터베이스에서는 날짜 및 문자 데이터 역시 크기 비교가 가능하다. 그렇기 때문에 날짜 및 문자 데이터 역시 MAX, MIN 함수를 사용할 수 있다.
예) 부서 번호가 20인 사원의 입사일 중 제일 최근 입사일 출력하기
(입사 연도가 제일 큰 사원이 최근이다. 반대로 제일 오래된 입사일은 MIN을 쓴다.)

4) 평균 값을 구하는 AVG 함수
-- 기본 형식
AVG ([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[평균을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
-- 분석하는 용도 (OVER절 추가)
AVG ([DISTINCT, ALL 중 하나를 선택하거나 아무 값도 지정하지 않음(선택)],
[평균을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법을 지정)(선택)- 숫자 또는 숫자로 암시적 형 변환이 가능한 데이터만 사용할 수 있다.

7-2. 결과 값을 원하는 열로 묶어 출력하는 GROUP BY절
1) GROUP BY절의 기본 사용법
- 여러 데이터에서 의미 있는 하나의 결과를 특정 열 값별로 묶어서 출력할 때 데이터를 '그룹화'한다고 표현한다.
- SELECT문에서는 GROUP BY절을 작성하여 데이터를 그룹화 할 수 있는데 다음과 같이 순서에 맞게 작성하며 그룹으로 묶을 기준 열을 지정한다.
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY [그룹화할 열을 지정(여러 개 지정 가능)]
ORDER BY [정렬하려는 열 지정]- GROUP BY절에 명시하는 열은 여러 개 지정할 수 있다. 먼저 지정한 열로 대그룹을 나누고 그 다음 지정한 열로 소그룹을 나눈다.
- GROUP BY절에는 별칭이 인식되지 않는다. 즉 열 이름이나 연산식을 그대로 지정해 주어야 한다.
예) 부서별 평균 급여 출력하기

예) 부서 번호 및 직책별 평균 급여로 정렬하기

2) GROUP BY절을 사용할 때 유의점
- 다중행 함수를 사용하지 않은 일반 열은 GROUP BY절에 명시하지 않으면 SELECT절에서 사용할 수 없다.
예) GROUP BY절에 없는 열을 SELECT절에 포함했을 경우 에러 발생

7-3. GROUP BY절에 조건을 줄 때 사용하는 HAVING절
- HAVING절은 SELECT문에 GROUP BY절이 존재할 때만 사용할 수 있다.
- HAVING절은 GROUP BY절을 통해 그룹화된 결과 값의 범위를 제한하는 데 사용한다.
예) 각 부서의 직책별 평균 급여를 구하되 그 평균 급여가 2000이상인 그룹만 출력해보기

1) HAVING절의 기본 사용법
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY [그룹화할 열을 지정(여러 개 지정 가능)]
HAVING [출력 그룹을 제한하는 조건식]
ORDER BY [정렬하려는 열 지정]- 기본 형식에서 알 수 있듯이 HAVING절은 GROUP BY절이 존재할 경우 GROUP BY절 바로 다음에 작성한다.
- GROUP BY와 마찬가지로 별칭을 사용할 수 없다.
2) HAVING절을 사용할 때 유의점
- WHERE절 : 출력 대상 행을 제한
- HAVING절 : 그룹화된 대상을 출력에서 제한
- 그룹화된 대상을 출력에서 제한해야할 때 HAVING절을 사용하지 않고 WHERE절을 사용하면 SELECT문이 실행되지 않고 오류가 발생한다.
예) HAVING절 대신 WHERE절을 잘못 사용했을 경우
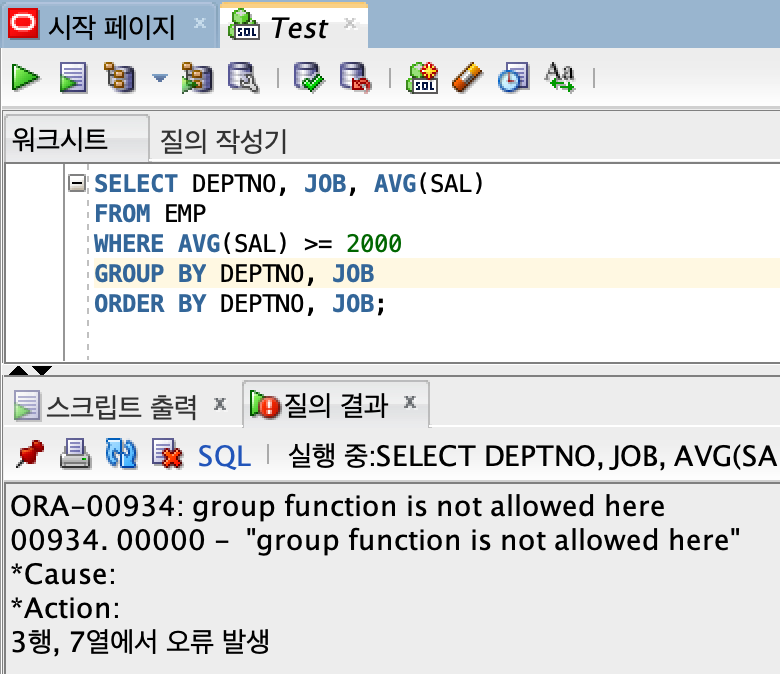
3) WHERE절과 HAVING절의 차이점
- HAVING절과 WHERE절을 모두 사용한 SELECT문이 어떻게 동작하는지 살펴보자
예1) WHERE 절을 사용하지 않고 HAVING절만 사용한 경우

예2) WHERE절과 HAVING절을 모두 사용한 경우

- WHERE절을 추가한 SELECT문에서는 10번 부서의 PRESIDENT 데이터가 출력되지 않는다. 이는 WHERE절이 GROUP BY절과 HAVING절을 사용한 데이터 그룹화보다 먼저 출력 대상이 될 행을 제한하기 때문이다.
- WHERE절의 제한으로 급여가 3000을 초과한 사원의 데이터는 결과에서 먼저 제외되므로 급여가 3000을 초과한 사원의 데이터는 그룹화 대상에 속하지 못하게 된다.
- 따라서 그룹이 만들어지기 전에 걸러진 데이터는 그룹화가 진행되지 않는다.
- GROUP BY절로 그룹을 나누는 대상 데이터를 처음부터 제외할 목적이라면 WHERE절을 함께 사용한다. 즉, GROUP BY절을 수행하기 전에 WHERE절의 조건식으로 출력 행의 제한이 먼저 이루어진다는 것을 기억하면 된다.
7-4. 그룹화와 관련된 여러 함수
1) ROLLUP, CUBE, GROUPING SETS함수
- ROLLUP, CUBE, GROUPING SETS 함수는 GROUP BY절에 지정할 수 있는 특수 함수이다.
1-1) ROLLUP, CUBE 함수
- ROLLUP 함수, CUBE 함수: 그룹화 데이터의 합계를 출력할 때 유용하게 사용할 수 있다.
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP [그룹화 열 지정(여러 개 지정 가능)];
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY CUBE [그룹화 열 지정(여러 개 지정 가능)];
- ROLLUP 함수와 CUBE 함수를 사용한 SQL문의 결과 값을 확인하며 사용법을 알아보자.
- 먼저 아래와 같이 부서 번호로 먼저 큰 그룹을 만들고 직책으로 소그룹을 나누어 각 그룹에 해당하는 데이터, 즉 각 부서의 직책별 사원수, 가장 높은 급여, 급여 합, 평균 급여를 출력하는 SQL문을 작성한다.

- ROLLUP 함수를 적용해보면 아래와 같다.

- ROLLUP 함수는 명시한 열을 소그룹부터 대그룹의 순서로 각 그룹별 결과를 출력하고 마지막에 총 데이터의 결과를 출력한다.
- ROLLUP 함수에 명시한 열에 한하여 결과가 출력된다는 것과 ROLLUP 함수에는 그룹 함수를 지정할 수 없다.
- CUBE 함수를 적용해보면 아래와 같다.

- CUBE 함수는 ROLLUP 함수의 결과와 더불어 부서와 상관없이 직책별 결과가 함께 출력되고 있다. (13~18행)
- 이렇듯 CUBE 함수는 지정한 모든 열에서 가능한 조합의 결과를 모두 출력한다.
- 그룹화 순서대로 출력해주는 ROLLUP 함수는 지정한 열 수에 따라 다음과 같이 결과 값이 조합된다. 즉 n개의 열을 지정하면 기본적으로 n+1개 조합이 출력된다.
| ROLLUP(A, B, C) 1. A 그룹별 B 그룹별 C 그룹에 해당하는 결과 출력 2. A 그룹별 B 그룹에 해당하는 결과 출력 3. A 그룹에 해당하는 결과 출력 4. 전체 데이터 결과 출력 |
- CUBE 함수는 지정한 모든 열의 조합을 사용하므로 다음과 같은 결과가 출력된다. 즉 n개의 열을 지정하면 2^n 개 조합이 출력된다.
| CUBE(A, B, C) 1. A 그룹별 B 그룹별 C 그룹에 해당하는 결과 출력 2. A 그룹별 B 그룹에 해당하는 결과 출력 3. B 그룹별 C 그룹에 해당하는 결과 출력 4. A 그룹별 C 그룹에 해당하는 결과 출력 5. A 그룹 결과 출력 6. B 그룹 결과 출력 7. C 그룹 결과 출력 8. 전체 데이터 결과 출력 |
- 따라서 두 함수는 지정한 열이 많을수록 출력될 조합이 많아진다. 특히 CUBE함수는 제곱수로 조합의 경우의 수가 올라가므로 감당하기 어려울 정도의 기하급수적인 증가가 일어난다.
- 이를 방지하기 위해 필요한 조합의 출력만 보려면 ROLLUP함수와 CUBE 함수의 그룹화 열 중 일부만을 지정할 수 있다. 이를 부분 또는 분할 ROLLUP, CUBE라고 한다.
- 다음은 그룹화 열을 두 개 지정하고 부분 ROLLUP을 적용한 예이다.
예1) DEPTNO을 먼저 그룹화한 후 ROLLUP 함수에 JOB 지정하기

예2) JOB을 먼저 그룹화한 후 ROLLUP 함수에 DEPTNO 지정하기

1-2) GROUPING SETS 함수
- GROUPING SETS 함수는 같은 수준의 그룹화 열이 여러 개일 때 각 열별 그룹화를 통해 결과 값을 출력하는 데 사용한다.
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY GROUPING SETS [그룹화 열 지정(여러 개 지정 가능)];- 앞에서 살펴본 ROLLUP과 CUBE 함수는 '특정 부서 내 직책별 인원수'처럼 열을 대그룹, 소그룹과 같이 계층적으로 그룹화해서 데이터를 집계했다.
- GROUPING SETS 함수는 부서별 인원수, 직책별 인원수의 결과 값을 하나의 결과로 출력할 수 있다. 즉 지정한 모든 열을 각각 대그룹으로 처리하여 출력하는 것이다. 아래 예제를 보면 그룹화를 위해 지정한 열이 계층적으로 분류되지 않고 각각 따로 그룹화한 후 연산을 수행했음을 알 수 있다.
예) GROUPING SETS 함수를 이용하여 열별로 그룹으로 묶어 출력하기

2) 그룹화 함수
- 그룹화 함수는 데이터 자체의 가공이나 특별한 연산 기능을 수행하지는 않지만 그룹화 데이터의 식별이 쉽고 가독성을 높이기 위한 목적으로 사용한다. 여기서는 GROUPING 함수와 GROUPING_ID 함수를 소개한다.
2-1) GROUPING 함수
- GROUPING 함수는 ROLLUP 또는 CUBE 함수를 사용한 GROUP BY절에 그룹화 대상으로 지정한 열이 그룹화된 상태로 결과가 집계되었는지 확인하는데 사용한다. GROUP BY절에 명시된 열 중 하나를 지정할 수 있다.
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
GROUPING [GROUP BY절에 ROLLUP 또는 CUBE에 명시한 그룹화 할 열 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE[그룹화 할 열];예) DEPTNO, JOB열의 그룹화 결과 여부를 GROUPING 함수로 확인하기

- 0은 GROUPING 함수에 지정한 열이 그룹화 되었음을 의미, 1은 그룹화되지 않은 데이터를 의미
- 이렇게 GROUPING 함수의 결과 값을 0,1로 구별하여 출력하면 현재 출력되는 데이터가 어떤 열의 그룹화를 통해 나온 것인지 알 수 있다.
- GROUPING 함수의 결과가 오직 0과 1로만 출력된다는 점을 고려하면 아래 예제와 같이 해당 열의 그룹화 없이 ROLLUP 또는 CUBE 함수로 처리하여 표기할 수도 있다.
예) DECODE문으로 GROUPING 함수를 적용하여 결과 표기하기

2-2) GROUPING_ID 함수
- GROUPING_ID 함수는 GROUPING 함수와 마찬가지로 ROLLUP 또는 CUBE 함수로 연산할 때 특정 열이 그룹화 되었는지를 출력하는 함수이다.
- 그룹화 여부를 검사할 열을 하나씩 지정하는 GROUPING 함수와 달리 GROUPING_ID 함수는 한 번에 여러 열을 지정할 수 있다.
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
GROUPING_ID [그룹화 여부를 확인할 열(여러 개 지정 가능)]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE[그룹화 할 열];- GROUPING_ID 함수를 사용한 결과는 그룹화 비트 벡터값으로 나타낸다. GROUPING_ID(a,b)와 같이 열을 두 개 지정한다면 출력 결과는 다음과 같다.
| 그룹화 된 열 | 그룹화 비트 벡터 | 최종 결과 |
| a,b | 0 0 | 0 |
| a | 0 1 | 1 |
| b | 1 0 | 2 |
| 없음 | 1 1 | 3 |
- 각 열의 그룹화 유무에 따라 0과 1이 나오는 것은 GROUPING과 같다. 하지만 GROUPING_ID 함수는 한 번에 여러 개 열을 지정할 수 있으므로 지정한 열의 순서에 따라 0,1 값이 하나씩 출력된다. 이렇게 0과 1로 구성된 그룹화 비트 벡터 값을 2진수로 보고 10진수로 바꾼 값이 최종 결과로 출력된다.
예) DEPTNO, JOB을 함께 명시한 GROUPING_ID 함수 사용하기

3) LISTAGG 함수
- LISTAGG 함수는 오라클 11g 버전부터 사용할 수 있는 함수이다. 그룹에 속해 있는 데이터를 가로로 나열할 때 사용한다.
- LISTAGG 함수에 대해 알아보기 전에 다음 SELECT문을 살펴보자. 이 SELECT문은 10번 부서에 속한 사원 이름을 구한다.

- 위와 마찬가지로 10번 부서 외에 다른 부서에도 사원 이름 데이터는 여러 개 존재한다. 하지만 GROUP BY절을 통해 DEPTNO 열을 그룹화해 버리면 ENAME 데이터는 GROUP BY절에 명시하지 않는 이상 SELECT절에 명시할 수 없다.

- 위와 같이 DEPTNO, ENAME 열을 모두 그룹화하여 출력하는 것도 한 방법이지만, 각 출력 정보에 비해 행이 너무 많아지기 때문에 각 부서별 사원 이름을 가로로 나열해서 출력하고 싶을 수 있다. 이때 LISTAGG 함수가 좋은 대안이 된다.
-- 기본 형식
SELECT [조회할 열1 이름], [열2 이름],...,[열N 이름]
LISTAGG([나열할 열(필수)], [각 데이터를 구분하는 구분자(선택 - 지정하지 않을 경우 NULL이 기본값)])
WITHIN GROUP(ORDER BY 나열할 열의 정렬 기준 열(선택))
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE[그룹화 할 열];예) LISTAGG 함수 사용하여 부서별 사원 이름을 나란히 나열하여 출력하기

4) PIVOT, UNPIVOT 함수
https://www.oracle.com/technical-resources/articles/database/sql-11g-pivot.html
'신입 개발자가 되기 위해 공부했던 독학 자료들 > Oracle' 카테고리의 다른 글
| CH 9. SQL문 속 또 다른 SQL문, 서브쿼리 (0) | 2022.03.08 |
|---|---|
| CH 8 . 여러 테이블을 하나의 테이블처럼 사용하는 조인 (0) | 2022.03.08 |
| CH 6. 데이터 처리와 가공을 위한 오라클 함수 (0) | 2022.02.26 |
| Oracle DB 테이블에서 컬럼의 고유키(PK, primary key) 찾는 방법 (0) | 2022.02.18 |
| CH5. 더 정확하고 다양하게 결과를 출력하는 WHERE절과 연산자 (0) | 2022.02.18 |



